
Beware delaying public deployment
Unless you also delay development and internal deployment

Context: This is a little less polished than my standard for our main blog relative to the topic’s importance but given how timely the post is and how little capacity I currently have to edit it, I’m publishing it anyway. I may publish a more polished version in the future, and could easily change my mind.
One strategy for ensuring AI safety is to, after an AI has been developed, test whether it is safe and wait to deploy it publicly until it passes these tests. Recent examples of this strategy include Anthropic voluntarily refraining from publicly deploying Claude Mythos for 4 months and counting, the US government placing export controls on Claude Fable to delay its deployment, and the government restricting GPT-5.6 from public deployment.
But there are big benefits to public deployment, and I’m not sure the downsides outweigh them. I’m worried that well-intentioned safety efforts may be causing harm by increasing the size of the capabilities gap between internal and public AIs. My tentative high-level recommendation is that you shouldn’t delay public deployment unless you also slow down AI development and internal deployment.
Basic argument for a small internal-public gap
I’ll focus in this section on the effect of delaying public deployment on the risk from misaligned takeover and extreme concentration of power, and discuss other risks in the next section. In either case, we’re worried about a somewhat similarly-shaped AI takeover, but in one case it’s done on behalf of a goal no human has, and in the other it’s done on behalf of a single human or small group.
A simplified version of the steps involved in an AI takeover look something like:
An AI is internally deployed. AI project employees can use it1 and it can autonomously do AI R&D, but it’s not available to the general public.2 It’s used to develop a more capable AI, let’s call it AI++.
AI++ is publicly deployed. If it has the desire and the capability to take over, then it does. Otherwise, it’s deployed internally, and we go back to step 1.
The direct catastrophe occurs during public deployment, i.e. step 2. So, safety efforts should target public deployment, right? For example, perhaps we should check if the model is safe, and then delay public deployment until it is safe to do so. Not so fast.
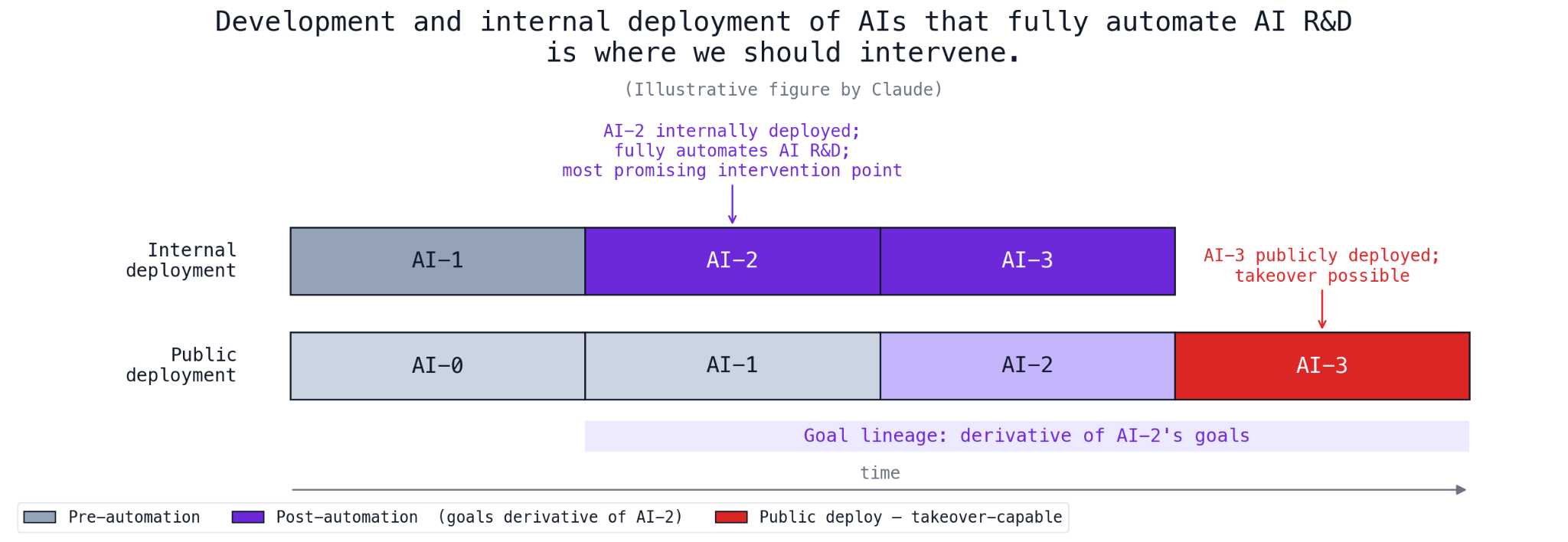
The goals of the AI that has the ability to take over in public deployment are determined by the goals of the AI that was internally deployed to automate AI R&D. Once a misaligned or aligned-to-few-humans AI is handed the keys to fully automate AI R&D, it’s in a very strong position. If you wait to target the public deployment of a future takeover-capable AI, it will likely be too late to intervene. There will be strong forces pushing toward deploying a takeover-capable AI, including agentic action by that AI and race dynamics (discussed further below).
In AI 2027, Agent-4 fully automates AI R&D in late 2027, building a misaligned successor Agent-5. By Dec 2027, Agent-5 is a misaligned superintelligence and deferred to by AI company and government leadership. We need to intervene before that point. It’s way too late when in 2030, an Agent-5 descendent actually kills off humanity.
Furthermore, delaying public deployment might be very costly. A large gap between public and internal models makes it more likely that the pace of AI capabilities outpaces society’s ability to understand and react to the technology. It puts frontier AI capabilities into the hands of a broad range of actors, lowering concentration of power. Additionally, there are many existentially useful applications that public deployment unlocks: AI for epistemics and coordination, uplifting technical safety research via research automation and better AIs to study, etc.
In AI 2027, an intelligence explosion seen only by the leading company and a few senior government officials combined with a months-behind public deployment contributes to a lack of effective action. Some of the benefits of public deployment could be obtained by deployment to a select group of external safety researchers, policymakers, and/or businesses. However, a full public deployment is valuable for understanding AIs’ true capabilities and increasing broad societal awareness.3
Counter-considerations
Effect on catastrophic misuse risk
One objection is that while public deployment may reduce risks from misalignment and extreme concentration of power, it increases catastrophic misuse risk from human actors, which outweighs the misalignment risk reduction. Risk pathways could include AI-assisted bioweapons and cyberattacks. I think that for current Mythos-level models catastrophic risk is quite low.
For future models, it’s possible there will be real tradeoffs. Delaying public deployment of the first models with a non-negligible risk of catastrophic misuse probably decreases short-term risk. In the medium-long term (which in AI might mean ~1-5 years), it’s less clear. Iterative public deployment is helpful for understanding the risks that models pose, and deploying publicly allows for a wider range of defenders to guard against misuse. Furthermore, if misuse risk is dominated by risk from novel technologies developed by future superintelligences, then what matters most will be whether society has generally navigated AI takeoff well rather than specific bio or cyber defenses; this points toward delaying public deployment being bad.
The situation may also vary based on the risk; for example, biorisk likely has a worse offense-defense balance than cyber, but is easier to mitigate via refusals without hurting defenders.
It seems possible that the best strategy for near-medium term (and maybe long-term) catastrophic misuse would be to delay public deployment enough to never push the frontier, and keep the internal-public gap high so that defenders have as big an advantage as possible. This strategy would require discipline to execute, and would be quite costly economically. If there later ended up being a jump in public deployed model capabilities, the delays could end up having hurt the situation because society might not be as prepared as if the improvement were more continuous.
Summing up, it seems like delaying public deployment is good for near-term misuse, unclear for medium-term misuse, and likely but not conclusively bad for long-term misuse. Plus, relative to iterative public deployment, the strategy is non-robust as introducing big capability jumps is dangerous. If one included extreme concentration of power risk as a misuse risk, then delaying public deployment seems likely bad. Overall my guess is that on most people’s beliefs and value systems, public deployment looks good, unless one is focused narrowly on human misuse risk on the timescale of weeks-months.
Some thoughts on how delaying public deployment affects other AI risks and upsides in a footnote.4
Avoiding unnecessary delays
One might object that if we simply evaluated AIs’ safety for public deployment correctly, this would suffice. We wouldn’t see unnecessary delays, and we wouldn’t deploy a takeover-capable but unsafe model.
The unnecessary delays may have already started. I tentatively believe that it would have been best to release Claude Mythos soon after it was trained.5 Nevertheless, the first version of Mythos was internally deployed on Feb 24, 4 months ago, and is yet to be publicly released. In my view, Mythos is not at the level of posing a significant risk of global catastrophe. While there are some upsides of delaying public release, the downsides seem higher.
Never deploying until it’s actually safe
Another hope is that we could avoid the public deployment of a takeover-capable AI, i.e. one that could confidently take over the world given a typical public deployment. After all, the capability level required to directly take over while internally deployed is higher than the level needed to take over while publicly deployed.
This is in theory possible but in practice seems highly unlikely to work, leaving the earlier internal deployment as a more promising intervention point. A takeover-capable AI likely needs to be broadly superhuman, and thus be very superhuman in some domains.
It seems very difficult to stop the public deployment of a misaligned superhuman AI due to:
Alignment faking. A takeover-capable AI may be capable of appearing safe, such that people don’t think there is a problem in the first place.
Agentic action by the AI. A takeover-capable AI may be capable of anticipating whatever strategies humans will use against it, and countering them. For example, outmaneuvering them in the political struggle regarding when to publicly deploy.
Race dynamics plus extreme usefulness. There may be domestic and/or international race dynamics pointing toward public deployment, given the AIs’ extremely useful superhuman capabilities.
Exfiltration. Even if none of the above work out, the AI may be able to escape from the company and stage a takeover using rogue compute. Or other actors may be able to steal the model weights, then publicly deploy them.
AI R&D acceleration
Another downside of public deployment is AI R&D acceleration; in my view this is plausibly the biggest downside. Publicly deploying models allows other actors to use them for their AI R&D, by either automating their research or using their outputs for distillation. This both shortens timelines and decreases the lead of the leading actor. I think this is a substantial consideration, but my current guess is that it is outweighed by the benefits of public deployment. You might be able to implement safeguards that block usage of models for frontier AI R&D to blunt this effect, as Anthropic has begun attempting to do.6
Indirect effects
It may be that even if the direct effect is negative, delaying public deployment is a good step toward delaying internal deployment or AI development. This seems very possible to me; it probably depends substantially on the particulars of the situation. If this is the theory of change, then I hope that people explicitly acknowledge this, at least to themselves.
Implications
I’m wary of policies that increase the size of the internal-public gap. Examples of actions and regulation that have delayed public deployment or have the potential to:
Anthropic voluntarily refraining from publicly deploying Claude Mythos for 4 months and counting.
The US government placing export controls on Claude Fable to delay its deployment, and restricting GPT-5.6 from public deployment. (The Fable export control may have delayed internal deployment in addition to public deployment, though it didn’t delay development.)
EU AI Act. The EU AI Act classifies models with >1e25 FLOP as having “systemic risk” by default, and requires notification, evaluations, risk assessment/mitigation, some cybersecurity, and various other requirements in order to be deployed in the EU market.
SB 53. SB 53 requires that developers with >$500M in annual gross revenue, before publicly deploying a frontier model (>1e26 FLOP), publish a transparency report with catastrophic risk assessments, third-party evaluator involvement, and evaluations. The same requirements are also found in New York’s RAISE Act, which enters into force at the start of 2027.
[Proposal] Liability. Another prominent AI safety proposal is liability for substantial harm. We’re worried that this proposal could make things worse by delaying public deployment, while not affecting internal deployment given it doesn’t cause direct harm.
At a minimum, I think that when designing policies in this vein the downsides of public deployment should be carefully considered. I think these policies may be net negative, but I’m far from confident.
Overall, I think that the downsides of delaying public deployment are underdiscussed and underappreciated by safety-concerned folks. I hope to spark more awareness and further discussion.7
Acknowledgments
Thank you to Miles Kodama and Ryan Greenblatt for comments. All views in this post are my own.
It may be limited even within the AI company to a silo.
There may also be a limited external deployment, i.e. a deployment to a limited number of external partners like Project Glasswing. This doesn’t count as a public deployment.
Our guess is that a limited external deployment misses out on most of the benefits that a public deployment gives.
For non-existential concentration of power threat models, the argument is less similar, public deployment still looks broadly good as it levels the playing field. For having superintelligences act more wisely, how much internal deployment matters depends on how sticky you think aligned AIs’ goals and wisdom levels will be over the course of the intelligence explosion. Probably they are less sticky than the goals of misaligned AIs, so internal deployment matters less relative to public deployment, but on the other hand there is no catastrophe in public deployment that is being guarded against.
We actually think that, at least for models nearly or fully capable of automating AI R&D, the best policy would be for companies to release models publicly before being used for internal AI R&D. Also, if a model would pose unacceptable risk if it were internally or externally deployed, it might also be too dangerous to train due to risk of exfiltration or AIs convincing people to deploy them after they’re trained.
Another consideration is that internal deployment might allow the AI project to better assess its models’ alignment. We think this consideration carries some force but we’d prefer that models were deployed first in lower stakes settings than internal AI R&D.
Existing discussion includes: IAPS report, METR blog post, Apollo paper, MATS paper, our related post on dangers of training AGI in secret.
Implications: We should delay development and internal deployment, as per your subtitle.
I'm curious about the focus on takeover risk from externally deployed models. I guess that the risk of takeover from internally deployed models is much greater.